系统不是设计出来的,而是在反馈中长出来的
从 Lisp REPL 到 Vibe Coding 的自底向上协作
我最近做了一个《道德经》释义应用 在线版本。
它最初只是 Google AI Studio 生成的一个 静态页面。页面有一点设计感,可以阅读《道德经》,但没有 AI 能力,也没有复杂交互,更谈不上什么结构化理解、分章系统、跨端同步或者背诵模式。
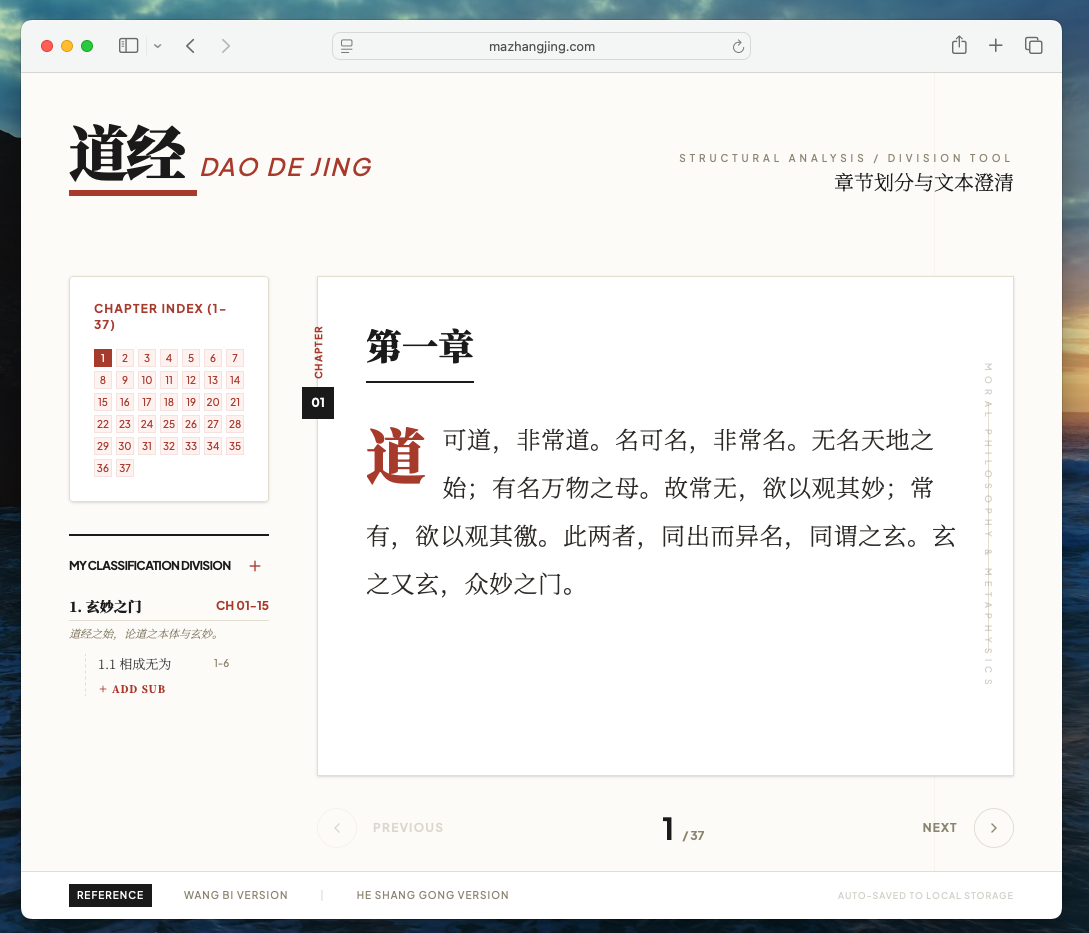
后来的样子完全不同。
这个应用逐渐长出了《老子》《庄子》《列子》的书籍导航,长出了分章定义、子章节、释义编辑,长出了“问 AI”、快捷短语、多章多选上下文,长出了 WebDAV 同步,长出了专门用于移动端回顾的背诵模式、暗黑模式和悬浮索引。
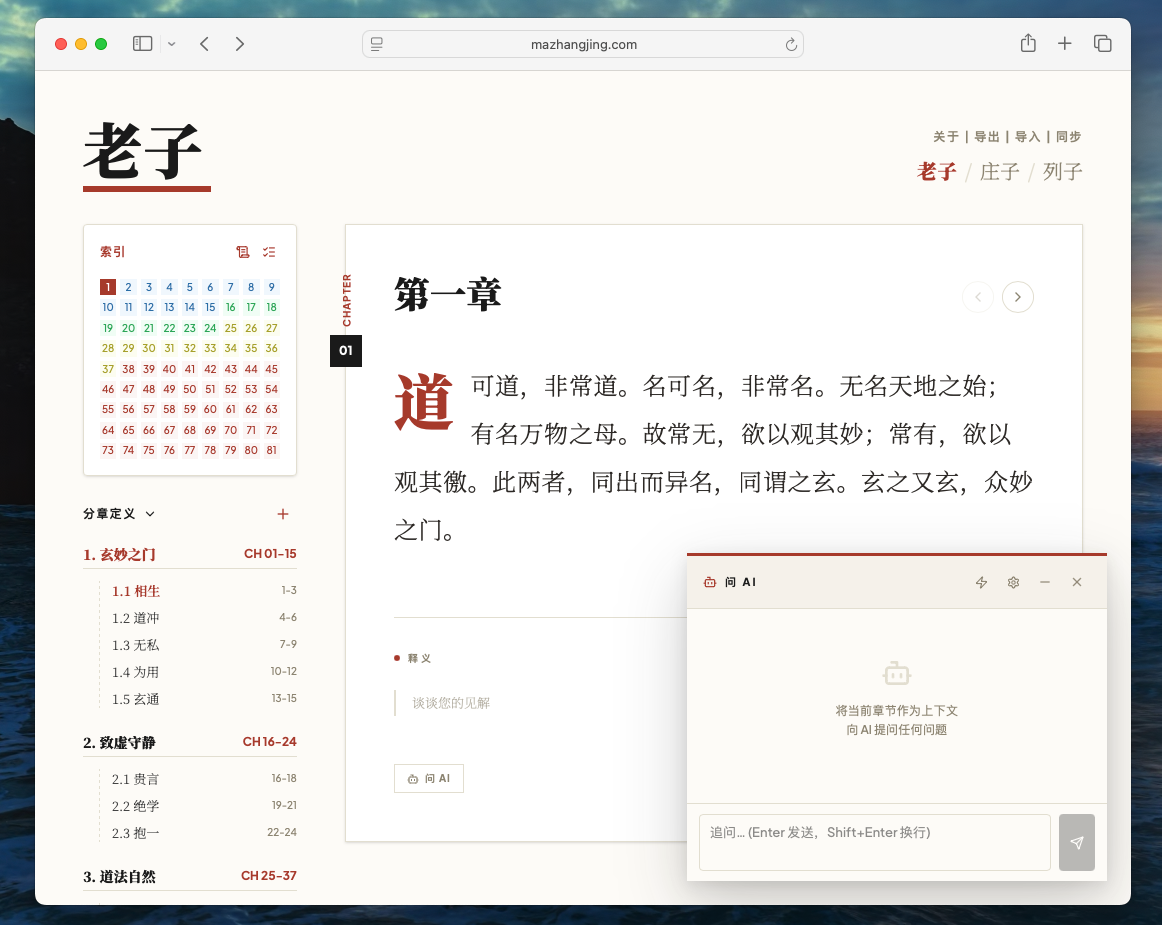
如果只看最终结果,它像是一个被规划过的应用。
但真实情况恰恰相反。
它不是先被完整设计出来,然后照着需求文档实现的。它是在我阅读《道经》《德经》的过程中,一点一点被真实使用逼出来的。
这件事让我越来越确信一个判断:
系统不是设计出来的,而是在反馈中长出来的。
这不是说设计不重要,也不是说架构不重要,而是说:在问题尚未被真正理解之前,过早设计往往只是把错误的直觉放大。真正有效的方式,是先让人的直觉进入一个更短、更密、更可反馈的循环。
这正是 Lisp REPL 给我的启发,也是我理解 Vibe Coding 和 Agent 协作的核心。
一、普通笔记软件为什么不够用了
这个应用的起点不是“我要做一个网页”。
它的起点是:普通笔记软件已经承载不了我对《道德经》的阅读方式。
普通笔记适合线性记录。第一章写一点,第二章写一点,第三章写一点。它可以保存摘抄、感想、批注,却很难让我同时看到整体结构。
我真正需要的是另一种东西:
每一章属于哪一个部分? 这一组章节和下一组章节是什么关系? 《道经》和《德经》内部如何分层? 某一章的释义如何服从整组主题? 我和 AI 讨论过的问题,如何回到具体章节和分章上下文? 当我想跨章节比较时,如何临时组合上下文?
也就是说,我面对的不是“记笔记”的问题,而是“建立结构”的问题。
传统笔记工具假定文本是线性的,但我的阅读已经变成了结构性的。我需要的不是一个更漂亮的笔记本,而是一个可以承载整体分章、局部释义、AI 讨论和长期回顾的工作台。
于是,我不得不做一个自己的工具。
这就是 Taoism 应用的真正起点。
二、LLM 是人类制造出的最强外部化直觉
我一直有一个判断:AGI 是最伟大的人类直觉。
更准确地说,当前的 LLM/Agent 是人类制造出的最强外部化直觉系统。
这里说“直觉”,不是说 LLM 具有人的意识,也不是说它等同于心理学意义上的系统 1。我的意思是,它在使用形态上极像一种外部化的直觉能力:它擅长在不完整的信息中进行模式补全,在模糊提示中生成可行方向,在尚未完全清晰的意图里给出一个可以继续推进的形体。
LLM 不是严格的第一性原理推导器。它更像一个巨大的上下文补全机器。它根据已有语境,生成下一步最可能、最自然、最可接续的东西。
这很像人的直觉。
直觉不是严密证明。直觉是模式识别,是经验压缩,是情境补全。人在熟悉领域里不需要每一步都显性推理,而是可以凭借已有经验快速行动。
这种能力会减少认知负载。
所以使用直觉常常是爽的。人在熟悉工作中进入心流,在学习的最近发展区中不断推进,在写代码时有一种“手感”,本质上都与较短的反馈循环、较低的认知阻力和可持续的模式补全有关。
但是直觉也会错。
真正的问题不是要不要使用直觉,而是:直觉离反馈有多远。
坏的设计不是直觉太多,而是直觉离反馈太远。
当一个未经校准的直觉被写成厚重的需求文档,被固化为一套庞大的架构,被分配给多个人执行时,它就不再是轻盈的直觉,而变成了沉重的沉没成本。
三、Lisp REPL 的快乐:让直觉贴着反馈走
我从 Lisp REPL 中得到过很强的启发:REPL 的魅力,不只是交互式执行代码。它真正改变的是思考方式。
在 REPL 中,程序员可以写一个表达式,立即求值,看到结果,再修正,再求值,再抽象。想法不需要先变成一个完整系统,才能被验证。它可以以最小形态进入现实,然后马上接受反馈。
这就是 Lisp Joy Coding 的来源之一。
它让程序员不必先形成一个巨大的、可能错误的整体直觉,然后在后面痛苦修正。相反,程序员可以在一个个小循环中不断校准自己的理解。
写一点。 运行。 观察。 修改。 再运行。 再抽象。
REPL 让思考始终贴着对象走。
它不是取消设计,而是把设计推迟到理解更充分的时候。它允许我们先探索,再抽象;先求值,再封装;先跑通,再重构。
这和我现在理解的 Agent 协作几乎是同一种方法,只不过反馈对象变大了。
传统 REPL 操作的是表达式。 Agent 协作操作的是意图。
四、Vibe Coding 是产品级 REPL
在 Vibe Coding 中,循环变成了这样:
prompt → code → run → observe → reprompt → refactor
我提出一个局部意图,Agent 生成一个可运行实现。我运行它,试用它,观察哪里顺手、哪里别扭、哪里不符合真实需求。然后我继续描述新的意图,让 Agent 修改。
这不是一次性生成完整产品。
它更像产品级 REPL。
在这个循环里,人的直觉不再悬空。它会不断落到一个可运行对象上。每一次运行,每一次试用,每一次不舒服,都会反过来修正人的判断。
这就是为什么 Vibe Coding 不应该被理解成“偷懒写代码”。
它更像一种新的认知接口:让尚未完全成型的想法,快速获得一个可交互的外壳。
传统软件开发经常要求我们先说清楚需求,再进入实现。但很多时候,需求不是预先完整存在的。需求是在使用中显现出来的。
人只有看到一个东西运行起来,才知道自己真正想要什么。
Agent 的价值正在这里:它把“从模糊直觉到可运行对象”的距离大幅缩短了。
五、Taoism 应用如何长出来
Taoism 应用几乎完整展示了这个过程。
最初的 Google AI Studio 初稿只是一个静态阅读页面。它有视觉效果,但没有真正进入我的阅读工作流。它不能承载分章,不能保存我的解释,不能让我把章节作为上下文喂给 AI,也不能支持跨端同步和背诵回顾。
但它足够成为第一个可运行对象。
这就够了。
有了这个对象,我开始真正使用它。使用之后,问题就逐渐出现了。
- 从静态阅读到分章系统
我首先发现,普通阅读页面不够用。
我不是只想逐章阅读《道德经》,而是想建立自己的分章体系。比如某几章共同构成一个主题,某一组章节是总论,某一组章节讲致虚守静,某一组章节讲道法自然,某一组章节讲德的形态和修行方式。
这些结构如果只写在笔记里,很快就会失去整体感。
所以应用开始长出分章系统。
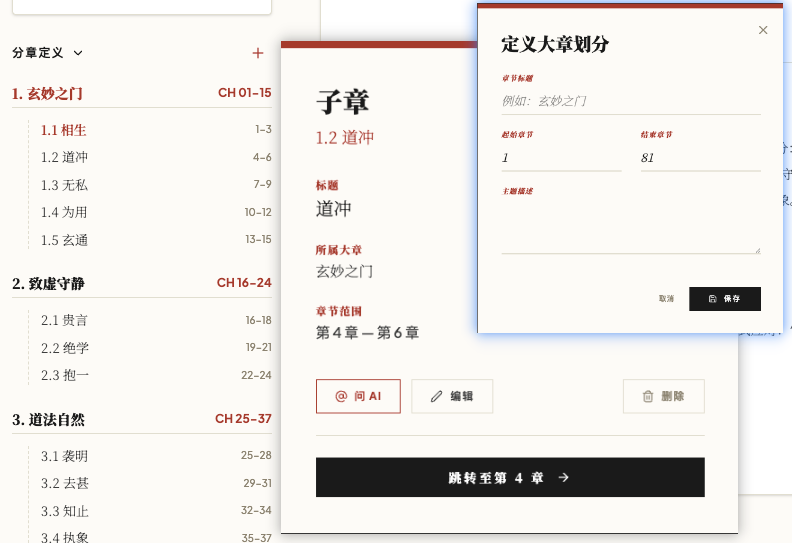
它不再只是显示文本,而开始承载我的结构判断。每一章不只是“第几章”,而是属于某个部分、某个主题、某个解释层级。
这一步之后,应用的性质已经变了。
它不再是阅读器,而是结构化理解工具。
- 从逐章问 AI 到快捷短语
接着,我开始逐章和 AI 讨论。
最开始,每次都是手动问:
这一章的基本释义是什么? 我的理解是否准确? 哪里需要修改? 这一章能用到什么地方? 它和前后章节有什么关系?
问多了之后,我发现这些问题高度重复。它们不是偶然问题,而是我的阅读方法本身。
于是快捷短语出现了。
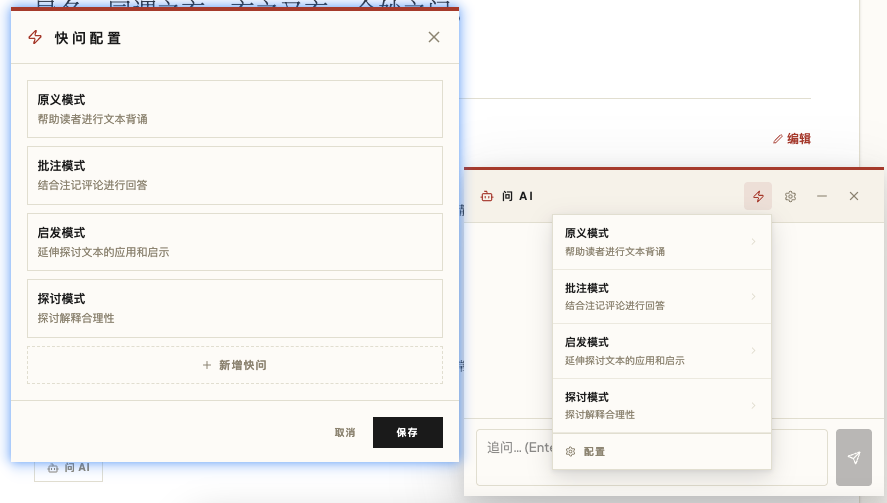
这看似只是一个小功能,但它背后的意义很大:工具开始固化我的思考动作。
高频意图不应该每次重新输入。高频意图应该被工具化。
快捷短语把我和 AI 之间反复发生的解释动作,压缩成了可以随时调用的按钮。
- 从分章上下文到自由多选上下文
后来,我又发现一个更复杂的问题:AI 上下文并不总是等于分章。
一开始,从左侧分章一键把整组章节喂给 AI 是合理的。因为我的主要结构就是分章。
但真实阅读很快打破了这个假设。
有时我只想问某个分章里的一两章。 有时我想跨分章比较几章。 有时我需要把不连续章节临时组合起来。 有时我对某个主题的理解,根本不服从已有分章边界。
于是,单纯从分章树里选择上下文就不够了。
应用开始长出索引层面的多选模式。用户可以从章节索引中自由选择任意章节,把它们作为上下文喂给 AI。
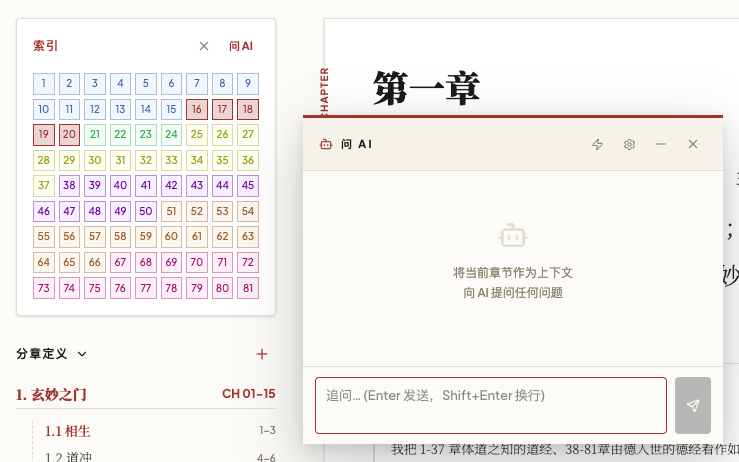
这里有一个重要区分:
分章是稳定结构,上下文选择是临时任务。
如果把临时任务强行绑定到稳定结构上,工具就会束缚思考。只有把二者分开,AI 才能真正服务于当下的问题。
这个功能不是预先设计出来的。
它是在使用中被逼出来的。
- 从本地工具到 WebDAV 同步
随着应用越来越深入我的阅读过程,它不再是一个临时页面,而变成了长期工具。
这时,跨端同步就变成刚需。
我的分章、释义、AI 设置、阅读状态都已经不只是应用数据,而是我的理解过程本身。如果这些数据只存在某一个浏览器里,它就不可靠。
于是 WebDAV 同步出现了。
这也不是炫技,而是因为长期使用自然要求连续性。
一个工具越贴近思考,它的数据就越珍贵。 一个工具越频繁使用,它就越需要跨端一致。
- 从功能生长到 Zustand 重构
但是,自底向上的生长也会带来问题。
功能一点点长出来,状态也一点点复杂起来。分章、释义、AI 设置、WebDAV 配置、本地状态、远端状态、同步时间、冲突处理,这些东西逐渐交织在一起。
早期的局部状态和 localStorage 方案开始变得吃力。
这时就需要重构。
于是我引入 Zustand,把应用状态集中起来,统一持久化,统一同步逻辑。这个重构不是一开始凭空设计出来的,而是在真实复杂度已经出现之后,被系统自身逼出来的。
这正说明了自底向上的关键:
自底向上不是不要架构,而是延迟架构。
好的架构不是在经验之前替代经验,而是在经验之后总结经验。
自底向上负责发现真实结构,阶段性重构负责固化真实结构。
- 从研究工具到背诵模式
当我完整读完《道经》和《德经》,完成分章、释义、讨论和整理之后,需求再次改变。
我不再只是要研究它,还要回顾它、背诵它、内化它。
研究模式需要编辑、问 AI、调整结构、查看分章。 背诵模式需要纯净、轻量、移动端友好、少干扰。
于是应用又长出了背诵模式。
它有不同的样式,有暗黑模式,有移动端适配,有悬浮章节索引,有更适合回顾的界面。
这一步说明,产品不是按功能列表增长的,而是随着使用阶段改变而改变的。
读的时候,需要阅读工具。 整理的时候,需要结构工具。 讨论的时候,需要 AI 上下文工具。 回顾的时候,需要背诵工具。
同一个系统,在不同阶段自然长出不同形态。
六、自顶向下的问题:过早冻结错误直觉
这段经历让我对自顶向下设计保持警惕。
自顶向下不是没有价值。复杂系统当然需要设计,需要抽象,需要架构。问题在于,很多自顶向下设计发生得太早。
太早的设计,往往只是把未经校准的直觉放大。
在问题尚未真正展开之前,人很容易以为自己已经理解了需求。于是写需求文档,画架构图,设计模块边界,定义数据结构。可一旦真实使用开始,才发现最初的模型并不准确。
这时,前期设计就变成了负担。
因为你不是在修正一个按钮,而是在修正整个错误抽象。 你不是在调整一个局部行为,而是在对抗已经沉没的结构成本。
自底向上的优势在于,它把错误控制在小范围内。
做错一个按钮,成本很低。 做错一个快捷短语,成本很低。 做错一个上下文入口,也还能调整。 但如果一开始就做错整个产品抽象,成本会非常高。
所以,自底向上并不是反理性。
它恰恰是面对不确定性时更理性的方式。
七、自底向上也有代价,但这不是问题
当然,自底向上不是没有缺点。
它容易造成局部堆叠。 它容易产生结构债务。 它容易让代码和状态在早期变得粗糙。 它可能先做出一个暂时可用但并不优雅的产品。
但这不是致命问题。
因为自底向上的正确姿势,本来就不应该是永远堆功能。它必须配合周期性的架构重构。
先小循环探索。 等真实结构浮现。 再阶段性重构。 然后继续进入下一轮探索。
这和 REPL 的方式完全一致:
先求值,再抽象。 先跑通,再封装。 先得到反馈,再建立结构。
真正的问题不是“自底向上会不会产生混乱”,而是有没有能力在适当时机清理混乱,把已经显形的结构抽象出来。
Vibe Coding 不是不要工程能力。
恰恰相反,它更需要工程判断。因为 Agent 可以快速生成局部实现,但什么时候该停下来重构,什么时候该统一状态,什么时候该重新划分边界,仍然需要人来判断。
Agent 放大的是直觉,而不是替代判断。
八、Agent 协作的正确姿势
所以,我现在越来越相信,和 Agent 协作的最好方式不是写一份完美文档,然后等待它实现。
那只是把旧的软件外包模式换成了 AI 版本。
更好的方式是:
抓住一个最小的不适。 让 Agent 生成一个可运行局部。 马上使用。 观察真实反馈。 继续修改。 等局部生长出稳定结构。 再进行阶段性重构。
也就是说,不是先完全想清楚,再开始做;而是在做的过程中,让自己逐渐想清楚。
这并不意味着没有方向。 它只是拒绝过早的完整性幻觉。
人需要方向,但不需要一开始就伪装成全知。 系统需要架构,但不需要在真实复杂度出现之前就过度架构。 Agent 需要提示,但不需要被一个错误蓝图锁死。
LLM 最强的地方,正是承接人的模糊意图,把它转化为可试用、可观察、可继续修改的东西。
它让人的直觉进入现实。
而一旦直觉进入现实,就可以接受反馈。 一旦接受反馈,就可以被校准。 一旦不断校准,就能逐渐长出系统。
九、回到《老子》:为大于其细
《老子》说:图难于其易,为大于其细。
这句话用在 Agent 协作上,几乎恰到好处。
困难的事情,要从容易处着手。 巨大的系统,要从细小处开始。
这不是鸡汤,而是一种方法论。
大系统从来不是凭空变大的。 大系统是由无数小循环长出来的。 每一个小循环都降低一点风险,暴露一点真实问题,校准一点错误直觉,沉淀一点稳定结构。
最后,当我们回头看时,会觉得系统好像被设计过。
但真实过程往往不是这样。
它是被使用逼出来的。 是被反馈修正出来的。 是被直觉推动、被现实校准、被重构固化出来的。
Taoism 应用对我而言就是这样一个例子。
它不是一个宏大设计的产物,而是我完整阅读《道德经》的过程中自然长出来的工具。它伴随着我的分章、理解、追问、整理和背诵,逐步变成了现在的样子。
所以我并不认为 Vibe Coding 的真正价值只是“写代码更快”。
它真正改变的是系统生成的方式。
过去,我们常常要求自己先把需求说清楚,再开始做。 但现在,Agent 让我们可以先做一个局部,再通过局部反馈逐渐说清楚需求。
这是一种更接近直觉的开发方式,也是一种更接近真实使用的设计方式。
LLM 是外部化直觉。 REPL 是短反馈循环。 Vibe Coding 是二者在产品开发中的结合。
系统不是设计出来的,而是在反馈中长出来的。